
Task-based LLM routing is the process of routing or directing users’ requests and inputs to the most suitable Large Language Model for the specific requirements and complexity of each task. This process matches tasks with the exact models that are optimized for those specific sets of capabilities. Task-based LLM routing ensures a low latency rate and reduces cost while maintaining balanced performance and scalability with smart allocation of resources.

What you will explore in the article
Importance of Task-Based LLM Routing
“A right person for the right job” Not every LLM is designed to perform every task; some prompts just need speed, while others need deep reasoning and analysis. Task-based LLM routing helps direct the complexity of the task to the right model for the right job.
1. Performance Optimization
Fine-tuned models for specialized purposes outperform general-purpose AI models in niche-specific tasks. For example, models that are fine-tuned on finance data achieve high accuracy in fintech, and a researcher benefits from a narrative or foundational model. Thus, LLM routing makes sure the input queries are transfered to expert models in specific niche or category to reduce latency and cost with better performance
2. Cost Optimization
Models like Gemini 2.5 Pro and GPT-4 are expensive LLMs; reserving these premium models only for complex queries and routing less complex tasks to the cost-efficient alternative reduces operational expenses.
3. Reduced Latency
Light models process faster than the bigger models. For real-time applications like trading bots, chat assistants, and chatbots where speed is needed, routing to these lighter and faster models improves user experience.
4. Scalability and Flexibility
The modularity of multi-tenant SaaS platforms serves diverse clients with their tiered routing. Basic-tier users get lightweight models, and enterprises get access to specially fine-tuned, niche-specific LLMs for complex tasks.
5. Reliability and Fallback Options
Task-based routing can include a fail-safe system in case the primary model fails and the system automatically routes to the alternative easily. For instance, if a foundational model for research exceeds the latency thresholds, the query autonomously shifts to the alternative model to maintain the consistency and accuracy.
Common Use Cases
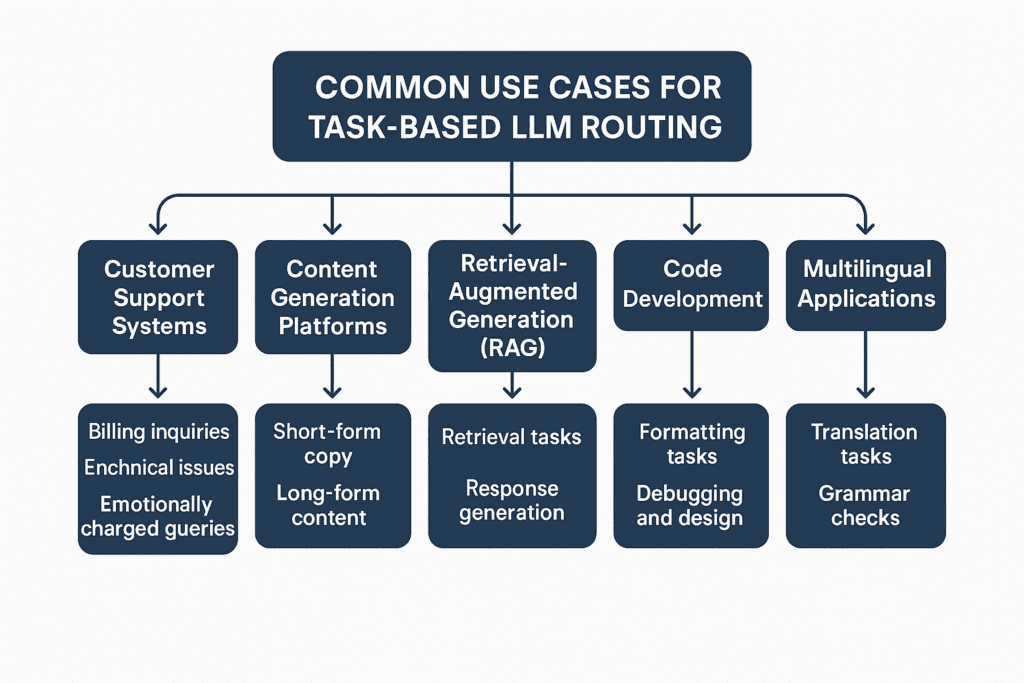
1. Customer Support
Task-based LLM routing can be used in customer support, where AI assistants can route technical issues to general-purpose models and billing inquiries to rule-based LLMs. It will reduce upsurge to human agents while maintaining customer satisfaction scores.
2. Content Generation
Generative AI tools for marketing route general and quick queries like “headlines” and “ad captions” to lighter LLMs, while long-form content creation like “whitepapers” goes to the advanced and powerful models.
3. Retrieval-Augmented Generation (RAG)
RAG (Retrieval-Augmented Generation) systems split tasks that use small models for speed to retrieve data and utilize larger models to generate responses. This hybrid approach reduces latency and maintains accuracy.
4. Code Generation
Simple code formatting and generation tasks are routed to the lighter models, and the tasks related to debugging and architectural design are routed to the high-parameter LLMs.
5. Multilingual Applications
Some models are better fine-tuned for specific language tasks, and some other models can better summarize the text and documents. For example, RouterLLM is assigned to route grammar check and summarizing tasks to language-optimized models while routing simple transcription queries to the lighter models.
Steps to Building a Task-Based Routing System
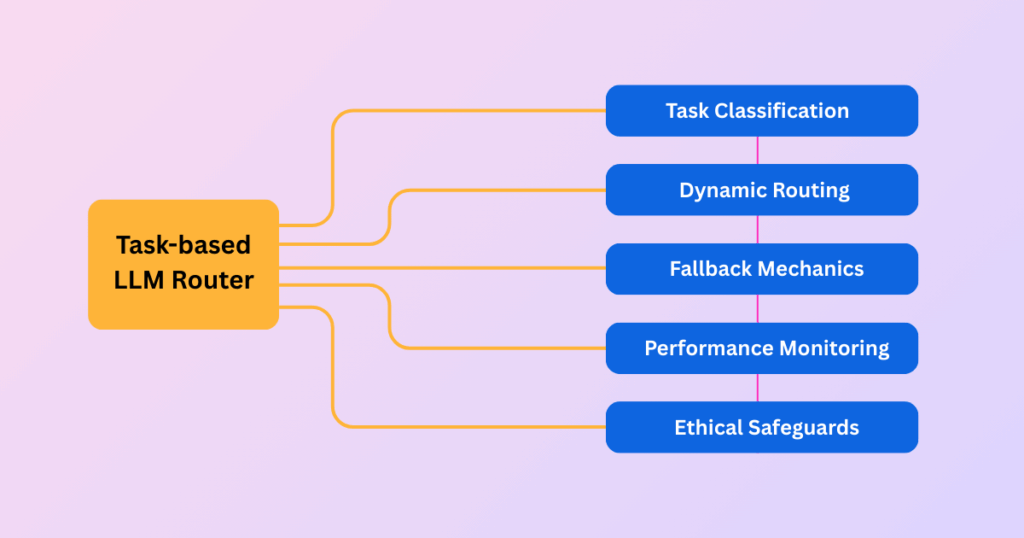
1. Task Classification
When configuring a task-based LLM router, the first step involves determining the purpose of each input from the user. You have multiple options here. The most useful method is employing keywords to quickly categorize tasks by scanning for specific terms or phrases in the query.
2. Dynamic Routing
If current metadata tags from upstream sources are available, these can direct routing decisions directly. For more advanced cases, a lighter LLM could analyze prompts to decide their intent, such as identifying requests for summarization, language translation, or sentiment assessment, enabling dynamic routing.
3. Fallback/Retry Mechanisms
Systems fail sometimes; defining backup models is a lifesaver for situations like model time-out and rate limits reached. For instance, if a code-generation model fails, the system reroutes to a secondary LLM with a set number of retry attempts.
4. Performance Monitoring
Set up track metrics and logs to get insight into which models handled which tasks, cost per query, usage, and error rate of each model to improve system performance. It helps understand and create an efficient task-based router.
5. Ethical Safeguards
Do a thorough audit of the models for bias and add filters for rerouting tasks that are sensitive in their nature, for example, legal queries that need a strict law to analyze and produce a legitimate response.
Taam Cloud’s Task-Based LLM Routing
Taam Cloud offers more than 200 Large Language Models, from OpenAI’s GPT-4 to Google’s most advanced AI model, Gemini 2.5 Pro. Taam Cloud’s automatic routing allows developers and enterprises to work efficiently with an unbreakable and unmatched AI experience.
1. Unified Model Gateway
Integrate 200+ LLMs via a single and secure API endpoint, including the models from OpenAI, Anthropic AI, Meta AI, Google AI, and all other major AI providers. Normalize outputs over providers to ensure consistency in downstream applications. See here.
2. Intelligent Routing Engine
Taam’s intelligent routing leverages semantic and context analysis and intent classification to route tasks dynamically. For instance, a healthcare platform using Taam Cloud directs patient queries to Med-PaLM for disease diagnosis while routing administrative tasks to Mistral 7B, reducing costs and latency and optimizing performance.
3. Real-Time Analytics
Monitor key performance indicators like cost per query, model usage, and accuracy through a simple yet powerful dashboard via Taam Cloud’s AI Observability. It allows developers and enterprises to optimize the cost and performance of their AI models.
4. Low-Code Workflows
Easily define routing rules without having extensive experience in coding; for example, simply write “Route all customer support queries to Mistral 7B and all financial queries to Claude 3 Sonnet,” and Taam Cloud will generate its logic for you.
5. Enterprise-Grade Security
Taam Cloud has implemented global standard security and privacy measures for increased data integrity and security. Being compliant with GDPR, SOC 2, and HIPAA, Taam Cloud handles data with encryption that converts data into an unreadable format, only allowing authorized personnel to access and use it.
Smart LLM routing with Taam Cloud
Smart task-based LLM routing systems can save a lot of time by implementing and routing tasks automatically to the most appropriate models for better performance, speed, and accuracy. While implementing and maintaining manual routing takes attention and time, that results in discontinuity in productivity.
You are a developer seeking to build an intelligent application using LLMs or an enterprise looking to automate business workflow and customer support services; try Taam Cloud, a smarter and more efficient platform for all your AI workloads.
Ready to optimize your AI productivity with Taam Cloud? Schedule a free consultation to design a custom implementation plan.
